Deploy a PostgresSQL database on Kubernetes with CloudNativePG

We recently wrote about how, since late 2019, the landscape for running PostgreSQL on Kubernetes has transformed. Today, it’s not just a bold choice for those risky DBAs with nothing else to lose. Running PostgreSQL on Kubernetes has become not just a viable but even potentially a superior way to manage database workloads, especially if you are already invested on Kubernetes.
You read more on: "Should you run PostgresSQL on Kubernetes?" in our first part of this series.
Managing database workloads on Kubernetes isn’t “easy” by any stretch of the imagination but with the emergence of well-maintained open-source operators like CloudNativePG, we now have the best of both worlds: the ability to run PostgreSQL, the most admired database in 2024, alongside the automation, scalability, and benefits of Kubernetes architectures.
Sign up and explore Distr
Distr is a battle tested software distribution platform that helps you scale from your first self-managed customers to dozens and even thousands.
What is CloudNativePG?
CloudNativePG is a massively popular open-source Kubernetes operator for managing PostgreSQL clusters. Built as a CRD, CloudNativePG extends Kubernetes capabilities, allowing for the wholistic management of database workloads, in a way that solely using StatefulSet would never be able possible.
It defines a Cluster resource representing a PostgreSQL cluster, including a primary instance and optional replicas for high availability and read query offloading within a Kubernetes namespace. Applications within the same Kubernetes cluster connect seamlessly to the PostgreSQL database through a service managed by the operator. External applications can access PostgreSQL using a LoadBalancer service, which can be exposed via TCP with the service template capability.
Originally developed by EDB and released as open source under the Apache License 2.0, CloudNativePG was submitted to the CNCF Sandbox in September 2024. You can find the source code on GitHub.
Main CloudNativePG features
We’ve already covered some of the main features in part one of this blog series. Here are some additional features though:
- Cross-Cluster Replication: Enables high availability and disaster recovery across multiple Kubernetes clusters.
- Multi-Tenancy Support: Allows multiple PostgreSQL clusters to run within a single Kubernetes environment, efficiently sharing resources.
- Advanced Connection Pooling: Integrates with connection pooling tools to optimize resource usage and reduce latency for high-traffic applications.
- Point-in-Time Recovery (PITR): Enables restoration of databases to a specific moment, crucial for recovering from data corruption or accidental deletions.
- Environment Flexibility: Compatible with various cloud environments, including private, public, and hybrid setups.
- WAL File Backup on Object Stores: Supports streaming write-ahead log (WAL) files to object storage like Amazon S3 or GCS.
- Client TLS/SSL Connections: Secure communication between PostgreSQL clients and the database clusters, protecting data in transit.
- Exposing Cluster Metrics for Observability Purposes: exposing metrics that can be easily leveraged to monitor database health, performance, and resource utilization with tools like Grafana.
In this blog post we will configure these last three features. But for instructions on how to enable and configure the other CloudNativePG features, reference the official CloudNativePG documentation.
Creating our first PostgreSQL cluster
I like to think of myself as a quick learner, but as a relative novice to PostgreSQL database management and seeing as how there are so many different use cases and feature CloudNativePG has to offer, if we explored them all this blog post it would surely turn into a brick of a book. So in the spirit of keeping it simple, actionable, and realistic, let’s focus on setting up a straightforward PostgreSQL cluster using Glasskube.
This cluster will be set up from scratch using a straightforward Cluster definition file. It will automatically create a postgres superuser, which you can use to connect to and manage the PostgreSQL instances. We'll also configure access and authentication control to allow connections from any host to the app database, requiring SSL certificates for secure authentication. Along the way, we'll explore the purpose of WAL (Write-Ahead Log) files and set up backups to an AWS S3 bucket. Additionally, we'll enable pod metric exports to integrate with the kube-prometheus-stack, and import the pre-built CloudNativePG Grafana dashboard to get a great overview of the inner workings of out database cluster right out of the box. All installation needed will be done with Glasskube for simplicity. This setup serves as an excellent starting point for anyone new to CloudNativePG.
Prerequisites
- Kubernetes cluster (You can easily create a local cluster by using Minikube)
- kubectl is strictly speaking no dependency for installing packages via glasskube, but it is the recommended way to interact with the cluster. Therefore, it is highly recommended. Installation instructions are available for macOS, Linux, and Windows.
- Glasskube installed
Installation
Install Glasskube
If you already installed glasskube you can skip this step.
If not, glasskube can easily be installed the way you usually install packages for your operating system.
- macOS
- Linux
- Windows
- NixOS/Nixpkgs
On macOS, you can use Homebrew to install and update Glasskube.
brew install glasskube/tap/glasskube
You can install Glasskube using one of the package managers below.RPM-based installation (RedHat/CentOS/Fedora)
dnf install https://releases.dl.glasskube.dev/glasskube_v0.26.1_amd64.rpmDEB-based installation (Ubuntu/Debian)
curl -LO https://releases.dl.glasskube.dev/glasskube_v0.26.1_amd64.deb
sudo dpkg -i glasskube_v0.26.1_amd64.debAPK-based installation (Alpine)
curl -LO https://releases.dl.glasskube.dev/glasskube_v0.26.1_amd64.apk
apk add --allow-untrusted glasskube_v0.26.1_amd64.apk
If you are using a distribution that does not use one of the package managers above, or require a 32-bit binary, check out additional download options attached to our latest release.
Download the windows archive from our latest Release and unpack it using Windows Explorer.
You can either use the package temporarily in a nix-shell:
nix-shell -p glasskube
Or install it globally by adding pkgs.glasskube to your environment.systemPackages.
After installing Glasskube on your local machine, make sure to install the necessary components in your Kubernetes cluster by running glasskube bootstrap.
For more information, check out our bootstrap guide.
Install cloudnative-pg
- GUI 🖥️
- CLI 🧑💻
Start the UI via the command line:
glasskube serve
Install cloudnative-pg via the Glasskube UI by following the package customization steps below.
A package can be installed with a simple command.
glasskube install cloudnative-pg
The process will wait until the package got successfully installed.
Getting started with CloudNativePG to deploy a PostgreSQL cluster on Kubernetes
We already installed the CloudNativePG operator in the previous step, so we are ready to deploy our first PostgreSQL database cluster.
Deploy a simple 3-instance PostgreSQL cluster on Kubernetes
We’ll create a simple 3-instance PostgreSQL cluster which will by default create a postrgres superuser and a normal app user.
Here’s the minimal YAML configuration needed. Make sure to always specific a separate volume for the write-ahead-log for PostgreSQL, as we don't want to fill up all of our disk space with logs.
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: pg-glasskube-cluster
spec:
instances: 3
storage:
size: 1Gi
walStorage:
size: 1Gi
Apply this configuration:
kubectl apply -f pg-glasskube-cluster.yaml
This creates a PostgreSQL cluster with three instances and 1Gi of storage per instance. Once the cluster is up, you can connect to it using the service created by the operator.
Connect to our PostgreSQL database on Kubernetes
In order to connect to our PostgreSQL cluster we need to create a port forwarding to our databases via the Kubernetes service.
kubectl port-forward svc/pg-glasskube-cluster-rw 5432:5432
Next we need to extract the password generated from the secret generated automatically:
kubectl get secrets pg-glasskube-cluster-app --template={{.data.password}} | base64 -d
Now we can connect to our PostgreSQL database with.
psql -h localhost -U app app
SSL connection for PostgreSQL on Kubernetes
Let’s make sure that all connections to the app database in the cluster is secured with SSL certificates.
By adding the following to the pg-glasskube-cluster.yaml file
postgresql:
pg_hba:
- hostssl app all all cert
Once you’ve added the segment to the cluster definition you can re-apply the definition by running:
kubectl apply -f pg-glasskube-cluster.yaml
Generating SSL certificates
The CloudNativePG operator can act as its own Certificate Authority (CA) or be configured to trust an external CA. In this case, we will allow the default, and the operator will include its own CA, and the certificate we create will be signed by the operator's CA. This certificate will be required to authenticate connections to the app database.
We can use the CloudNativePG plugin for kubectl to create the SSL certificate, to install the plugin, run:
curl -sSfL \
https://github.com/cloudnative-pg/cloudnative-pg/raw/main/hack/install-cnpg-plugin.sh | \
sudo sh -s -- -b /usr/local/bin
Once installed we can create the certificate using the plugin:
kubectl cnpg certificate pg-glasskube-cluster-cert \
--cnpg-cluster pg-glasskube-cluster \
--cnpg-user app
To test that the app database is not protected and can only be accessed by using the generated certificate, let’s run the following cert-test deployment which is going to mount the needed CA and our generated certificate, once deployed we can run a test command from the cert-test pod to make sure it can access the app database.
apiVersion: apps/v1
kind: Deployment
metadata:
name: cert-test
spec:
replicas: 1
selector:
matchLabels:
app: webtest
template:
metadata:
labels:
app: webtest
spec:
containers:
- image: ghcr.io/cloudnative-pg/webtest:1.6.0
name: cert-test
volumeMounts:
- name: secret-volume-root-ca
mountPath: /etc/secrets/ca
- name: secret-volume-app
mountPath: /etc/secrets/app
ports:
- containerPort: 8080
env:
- name: DATABASE_URL
value: >
sslkey=/etc/secrets/app/tls.key
sslcert=/etc/secrets/app/tls.crt
sslrootcert=/etc/secrets/ca/ca.crt
host=pg-glasskube-cluster-rw
dbname=app
user=app
sslmode=verify-full
- name: SQL_QUERY
value: SELECT 1
readinessProbe:
httpGet:
port: 8080
path: /tx
volumes:
- name: secret-volume-root-ca
secret:
secretName: pg-glasskube-cluster-ca
defaultMode: 0600
- name: secret-volume-app
secret:
secretName: pg-glasskube-cluster-cert
defaultMode: 0600
Then verify that the Pod - Database connection works run:
kubectl exec -it deployments/cert-test -- bash -c \
"psql 'sslkey=/etc/secrets/app/tls.key sslcert=/etc/secrets/app/tls.crt sslrootcert=/etc/secrets/ca/ca.crt host=pg-glasskube-cluster-rw dbname=app user=app sslmode=verify-full' -c 'select version();'"
If you see the following output, you have configures SSL authentication correctly:
version
--------------------------------------------------------------------------------------
------------------
PostgreSQL 17.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 8.3.1 20191121 (Red Hat
8.3.1-5), 64-bit
(1 row)
Create a PostgreSQL WAL file backup in AWS
What is a WAL file?
Write-Ahead Logging (WAL) is a critical feature in PostgreSQL that logs changes before applying them to the database. It’s essential for crash recovery and replication, acting as a safety net that ensures data integrity. WAL records every change in a durable, sequential log, allowing the database to recover to a consistent state after a crash or replicate changes to standby instances. By backing up WAL files to an S3 bucket, we can restore the database to its previous state by replaying the logged transactions, effectively reconstructing the database to the point of the last recorded change.
Backing up WAL files ensures no data is lost between regular database backups. However, WAL files alone don’t recreate the entire database, they apply logged changes to an existing base backup during recovery.
Fully recreating an entire PostgreSQL database typically involves combining base backups with WAL files, but that’s beyond the scope of this blog post.
To back up WAL files to AWS S3, we are going to need to have the following:
- An S3 bucket
- An IAM user with a policy attached giving the user the requisite S3 permissions
- A Kubernetes secret containing the AWS user credentials
-
Create the S3 bucket and give it a relevant name
-
Create an IAM user and attach the following inline policy to the user:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": ["s3:GetObject", "s3:PutObject", "s3:ListBucket"],
"Resource": [
"arn:aws:s3:::test-cnpg-backup",
"arn:aws:s3:::test-cnpg-backup/*"
]
}
]
}
Then, create a Kubernetes secret for the S3 credentials:
kubectl create secret generic aws-creds \
--from-literal=ACCESS_KEY_ID=<ID_Value> \
--from-literal=ACCESS_SECRET_KEY=<Secret_Key_Value>
Then add the following section to the cluster spec:
backup:
barmanObjectStore:
destinationPath: 's3://<BUCKET_NAME>/'
s3Credentials:
accessKeyId:
name: aws-creds
key: ACCESS_KEY_ID
secretAccessKey:
name: aws-creds
key: ACCESS_SECRET_KEY
Reapply the updated cluster configuration:
kubectl apply -f pg-glasskube-cluster.yaml
You can check to see if the WAL backup is working as expected by checking the logs of any of the cluster pods.
kubectl logs <CLUSTER_POD_NAME>
If configured correctly, you can expect to find a new folder which is named the same of the cluster name created in the S3 bucket.
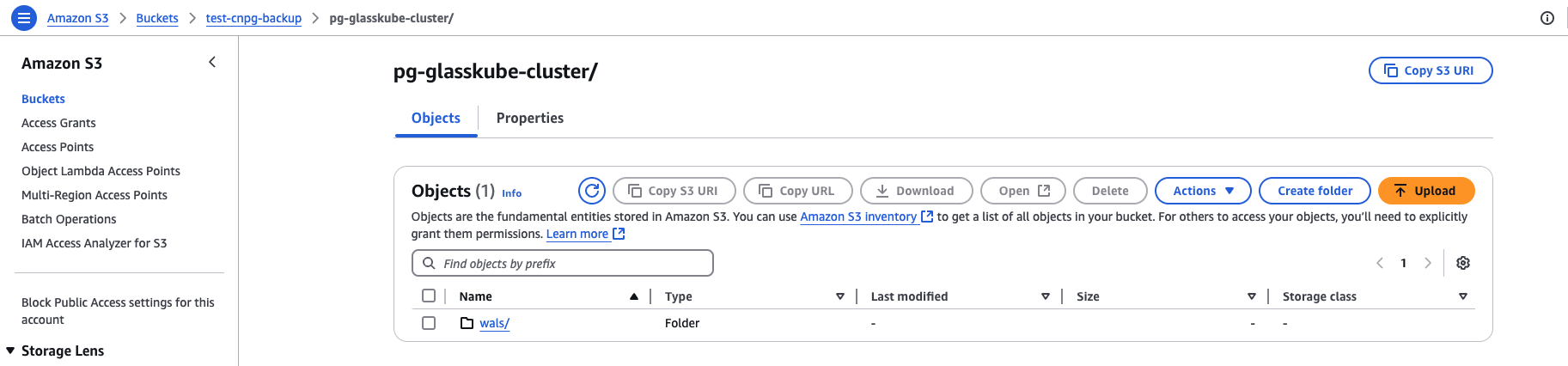
The complete Cluster definition file looks like this
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: pg-glasskube-cluster
spec:
instances: 3
storage:
size: 1Gi
walStorage:
size: 1Gi
postgresql:
pg_hba:
- hostssl app all all cert
backup:
barmanObjectStore:
destinationPath: 's3://test-cnpg-backup/'
s3Credentials:
accessKeyId:
name: aws-creds
key: ACCESS_KEY_ID
secretAccessKey:
name: aws-creds
key: ACCESS_SECRET_KEY
# We'll need this for the monitoring section below
monitoring:
enablePodMonitor: true
Monitor the PostgreSQL cluster with kube-prometheus-stack
With the cluster up and running, we can now leverage the CloudNativePG community-maintained dashboard to visualize key cluster metrics. To make this possible, we’ll need Prometheus to gather the metrics and expose them in a format Grafana can consume. The simplest way to set up the full monitoring stack is by installing the kube-prometheus-stack using Glasskube.
For detailed instructions, follow the full installation guide. You can install it via the CLI and provide the necessary value definitions when prompted.
glasskube install kube-prometheus-stack
Or by using the Glasskube console.
Grafana authentication: Once installed you can access the Grafana dashboard with default user admin and password prom-operator
Once inside Grafana then create a new dashboard and import an existing dashboard using the community-maintained CloudNativePG dashboard with ID 20417
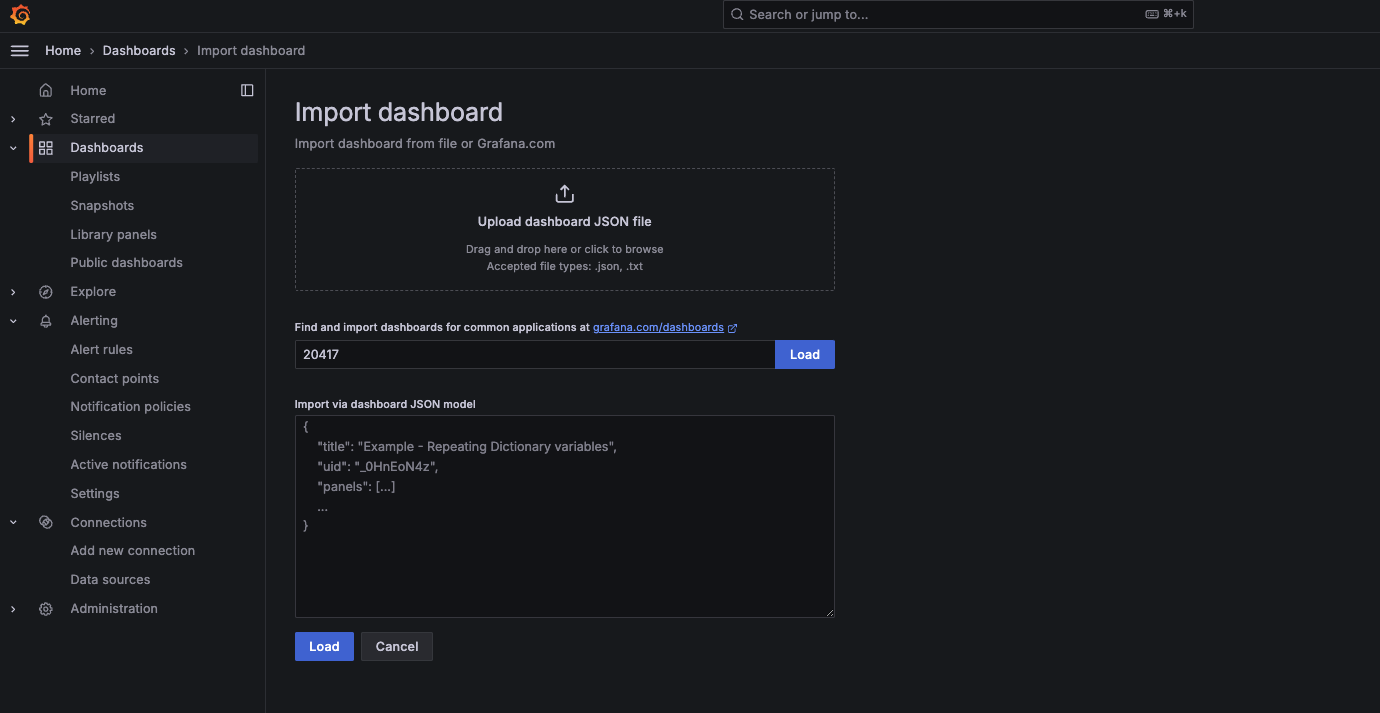
Give it a name, and after a few minutes you should see something similar to this
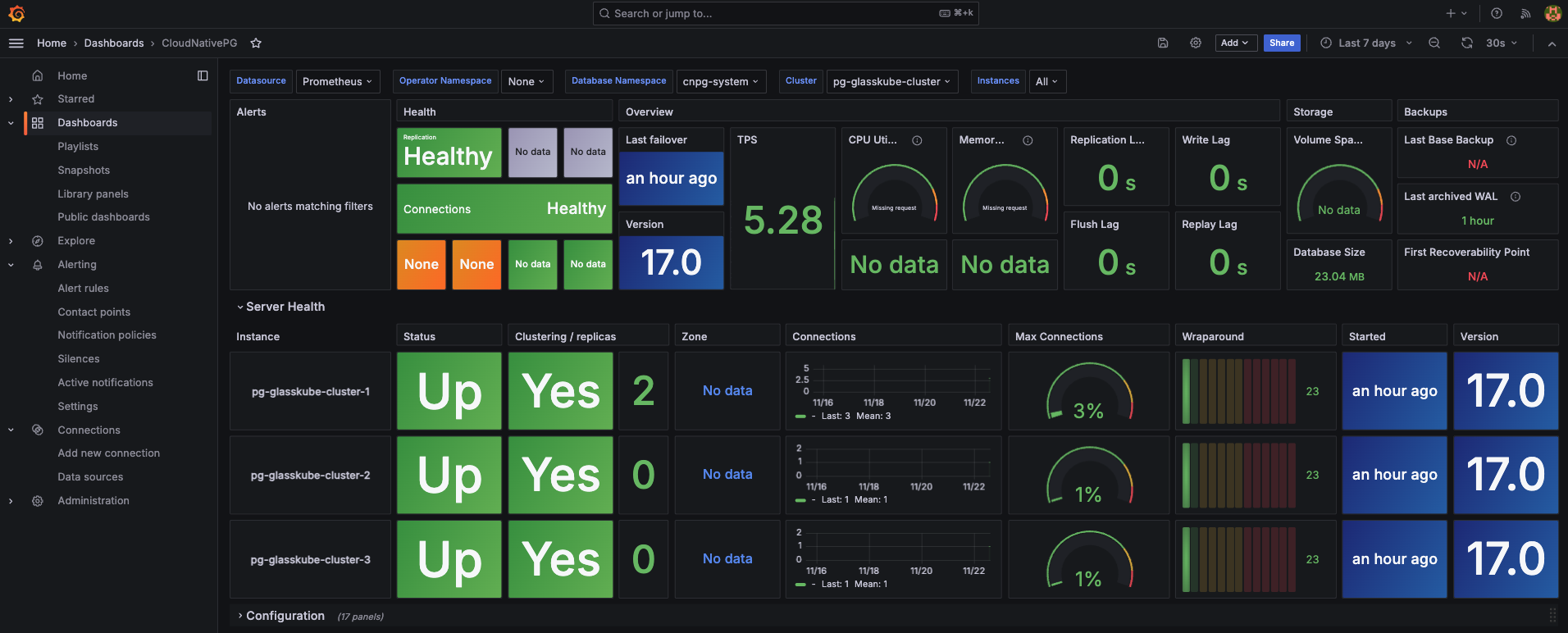
In this CloudNativePG guide, we walked through the initial setup of the CloudNativePG operator and introduced the basics of managing PostgreSQL clusters. We covered key features like enabling WAL file backups for disaster recovery, configuring TLS for secure database authentication, and deploying a monitoring stack to keep a close eye on your database cluster's health. Hopefully, this guide has been helpful and gives you a solid starting point for managing PostgreSQL clusters on Kubernetes with the CloudNativePG operator.
Sign up and explore Distr
Distr is a battle tested software distribution platform that helps you scale from your first self-managed customers to dozens and even thousands.