Should you run PostgreSQL on Kubernetes?


TLDR;
Do you hate it when articles don’t get straight to the point? I definitely do.
So if you’re in a hurry, here’s the answer: Yes! Running a PostgreSQL database cluster on Kubernetes is a viable, production-ready method for hosting database workloads. But it wasn't always that straightforward. Back when StatefulSets was the only Kubernetes primitive available, managing databases in Kubernetes had its challenges. With the maturity of purpose-built Kubernetes operators like CloudNativePG, the real limitations now lie in the skills and experience of the engineers managing these workloads.
That said, running PostgreSQL on Kubernetes won’t necessarily boost your security or solve resilience issues. However, it opens up significant potential for automation and extensibility that would be much harder to achieve otherwise.
Sign up and explore Distr
Distr is a battle tested software distribution platform that helps you scale from your first self-managed customers to dozens and even thousands.
Why focus on PostgreSQL?
Sure, database workloads aren’t limited to PostgreSQL. MySQL, MongoDB, and other database technologies also offer mature operators with useful features and interesting use cases, many of which could make for great future blog posts. But in this piece (and in the two to come), we’re focusing on PostgreSQL for a few reasons.
First, it’s the database we use internally at Glasskube, and we help several customers manage their production PostgreSQL workloads as well. Plus, it doesn’t hurt that PostgreSQL was rated the “Most Admired and Desired Database” in Stack Overflow’s 2023 Developer Survey.
Here are some of the things PostgreSQL has going for it
- Longevity: With over 25 years of innovation and development. PostgreSQL is a stable and trusted choice by many.
- Open-Source and Versatile: A multi-purpose database, PostgreSQL fits a wide range of workloads and use cases.
- High Availability: Supports a primary-replica architecture with a single primary and multiple read-only replicas, maximizing uptime and availability.
- Advanced Replication Protocol: Features like synchronous replication (transaction-level control) and cascading replication ensure data consistency and reliable read performance even between Kubernetes clusters.
- Disaster Recovery: Continuous backup and point-in-time recovery (PITR) enable reliable restoration from any point, providing strong resilience and operational security.
- Strong Community and Popularity: PostgreSQL is widely adopted and consistently rated as one of the most admired databases, making it a popular choice for many teams and projects.
PostgreSQL on Kubernetes, is it a good idea?
If you’d been in a coma for a decade and just woken up after Kubernetes v1.14, you’d be surprised to find the consensus on databases in Kubernetes has flipped. With Kubernetes v1.14, Local Persistent Volumes reached General Availability, and the operator/controller pattern really began to take off. This shift sparked a reassessment of whether database workloads belong in Kubernetes. But before we dive into why this could now be a good fit, it’s worth understanding why, not long ago, running databases in Kubernetes was sketchy, to say the least.
Initially, Deployments and StatefulSets were the only primitives Kubernetes had to handle workloads. Deployments were quickly ruled out for databases since they spin up pods unpredictably, assign random network IDs, and can’t ensure a specific replica remains the primary. StatefulSets improved things by indexing pods, making scaling predictable, assigning specific network IDs, and having the possibility to pair each replica to its own persistent storage. This means that if a replica fails, a new one can connect to the same persistent volume as its predecessor.
Yet as Viktor Farcic put it,
“The fact that the StatefulSet is a better choice than a Deployment doesn’t mean it’s a good choice.”
For true production-grade database workloads, StatefulSets still lack critical database features like:
- Backups
- Automated Failovers
- Replica Promotions
- Observability
And since StatefulSets weren’t enough, many determined that Kubernetes was not for Databases.
So why even consider running PostgreSQL DBs in Kubernetes?
Because things have changed. StatefulSets aren’t the only tools in the box anymore. Today, Kubernetes is widely understood not as a complete out-of-the-box solution but as a highly extensible platform. Its real power lies in its extensibility.
Instead of relying solely on Kubernetes-native storage, you can extend its capabilities with CSI storage plugins. And most importantly, instead of using StatefulSets, we now have purpose-built operators designed to manage complex, stateful workloads. These operators handle everything StatefulSets once did but add the full range of database-level features you’d expect in production.
Chris Milsted from Akamai put it well when he said,
“By putting your data into Kubernetes, none of your resiliency problems change. You still have to think about exactly the same problems, but it’s a lot easier and there are lots of nice automations and things that happen either from the Kubernetes side or from the CloudNativePG operator, that make your life a lot easier. It’s much simpler to reach automation and get things working without spending months on it.”
When incorporating the data layer of your architecture into a Kubernetes cluster, you gain the unified benefits of shared networking and compute resources, alongside Kubernetes-native features like self-healing, regional and availability zone diversification, and more.
Gabriele Bartolini, VP of Cloud Native at EDB and a well-regarded figure in the PostgreSQL community advocates running PostgreSQL on Kubernetes to achieve these key benefits:
- Application-Level Replication: By using PostgreSQL's native replication to synchronize data within and across Kubernetes clusters, rather than relying on storage-level replication. This approach, native to Kubernetes, is ideal for maintaining application resilience and state consistency.
- Availability Zone Optimization: By leveraging Kubernetes’ availability zones rather than isolating data centers in separate clusters. This enables automatic high availability with zero data loss and very low Recovery Time Objective (RTO) within a single region—out-of-the-box.
What alternative methods are there?
Running it directly on a VM
Sure you could do that, probably when a Kubernetes StatefulSet was your only alternative, nobody would judge you for doing so.
Using a managed DB service outside of your cluster
In many cases, deciding between running PostgreSQL on Kubernetes versus using a fully managed service feels a lot like weighing the trade-offs of SaaS versus self-hosted software in general. For many, including myself and our team, the extensibility and customization Kubernetes offers, combined with the relative ease of using an operator like CloudNativePG, make self-hosting a clear choice. Plus, the typically high cost of managed services only makes the decision to self-hosting on Kubernetes even easier. A comment on the /kubernetes subreddit put it well.
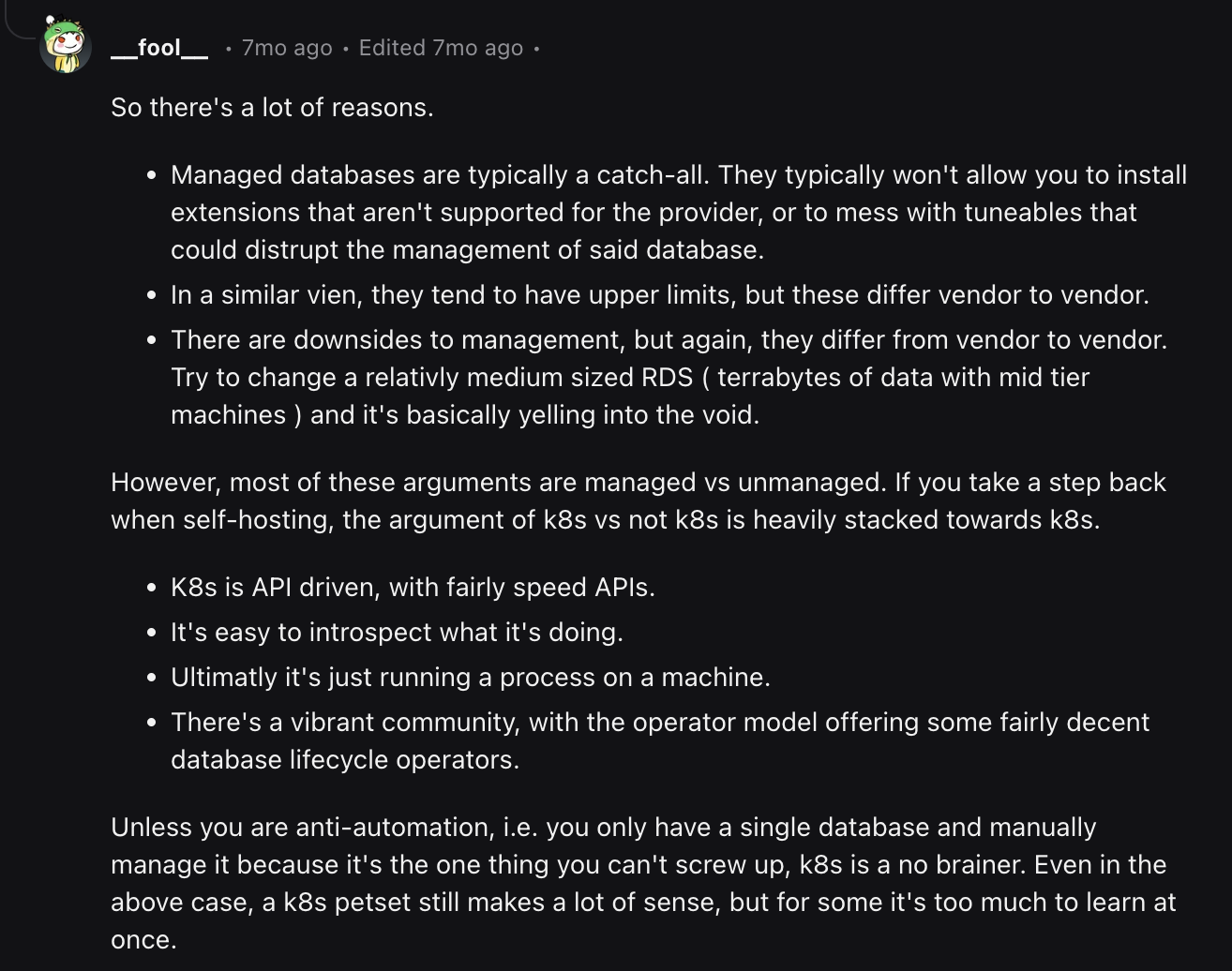
What do you need to run PostgreSQL on Kubernetes?

Largely there are three main ingredients required to be able to pull off efficient PostgreSQL management on Kubernetes.
-
Kubernetes Expertise: Your team or organization should have a solid understanding of Kubernetes to manage and troubleshoot the environment effectively.
-
PostgreSQL Expertise: A strong grasp of PostgreSQL is essential to configure, optimize, and maintain the database within a Kubernetes setup.
-
A Reliable Operator: Use a dependable operator to handle the full lifecycle management of PostgreSQL clusters, ensuring high availability and seamless scaling.
If you’re already running application workloads in Kubernetes but have a data layer outside of it, consult with an experienced professional before attempting to “lift and shift” your database workloads into Kubernetes, this process is far from straightforward. Likewise, if you’re starting from scratch in a new Kubernetes environment, it’s wise to get guidance from a seasoned professional who can help you make architectural decisions you won’t regret later on.
Speaking of the operator: What is CloudNativePG?

CloudNativePG is an open-source operator designed for managing PostgreSQL database clusters in Kubernetes. It’s loaded with features that make it production-ready and well-suited for high-availability PostgreSQL workloads.
Some of its key capabilities include:
- It’s Production-Ready: Built to handle production-grade workloads.
- It’s Kubernetes Operator: Fully integrated with the Kubernetes API.
- Automated Failover: Ensures high availability by automatically switching to a replica if the primary instance fails
- Fully Declarative: It makes managing PostgreSQL clusters with declarative configurations possible.
- Open-Source: Freely available and community-supported.
- Self-Healing: Automatically detects instance failures and re-provisiones databases.
- Cluster Management: Acts as a PostgreSQL cluster manager within Kubernetes.
- Enhanced Security: Supports mTLS for secure communication.
- Optimized Storage: Manages separate volumes for WAL files.
- Backup and Recovery: It has built-in features for backup and disaster recovery.
- Rolling Updates: Minimizes downtime during updates.
- Extended Kubernetes Controller: Adds enhanced PostgreSQL-specific functionality.
- Native Prometheus Exporters: Enables easy integration with monitoring tools.
- Direct PVC Management: Uses PersistentVolumeClaims (PVCs) directly to associate many types of storage targets.
- Application-Level Replication: Handles data replication at the application level for consistency.
- Kubectl Plugin: Offers convenient management through Kubernetes CLI.
What Storage Should You Use?
In Kubernetes, there are two main types of storage access:
- Network Storage: Typically accessed through Network File Systems (NFS), Container Storage Interface (CSI) plugins, or similar network-attached options. This is commonly used in Kubernetes but can introduce issues with throughput and latency, particularly in shared environments where multiple applications compete for I/O resources.
- Local Storage: Since Kubernetes v1.14, local storage can be directly attached to a node, including in bare-metal setups. Local storage is ideal for high-transaction or Very Large Database (VLDB) workloads. It provides a "shared-nothing" architecture, delivering higher and more predictable performance, which is particularly useful for workloads requiring fast and consistent access times.
Using local storage attached to the host where the PostgreSQL database is running is generally the best and most recommended way for production workloads. CloudNativePG is highly flexible, allowing you to use various storage types attached through Persistent Volume Claims (PVCs) for both active workloads and backups. In upcoming blog posts, we’ll explore how to set this up in practice.
This blog post is the first of a three-part series. In the upcoming posts, we’ll provide a simple guide to getting started with PostgreSQL on Kubernetes and dive into the implementation of CloudNativePG. Finally, we’ll explore PostgreSQL architecture patterns for Kubernetes workloads, wrapping up with a client use case that showcases advanced features like cross-cluster failover.
Don’t just take my word for it, industry leaders like Gabriele Bartolini and Chris Milsted have made a strong case for running PostgreSQL on Kubernetes, and they’ve articulated it better than I ever could. The rapid growth of database workloads on Kubernetes owes much to the work of communities like the Data on Kubernetes Community (full disclosure: I’ve collaborated with them in the Portuguese-speaking side of the community). Thanks to experts like these, open source contributions, and communities, the question posed in the title of this piece is answered with a resounding “yes”.
Make sure to also read our part 2 of this series on: "Deploy a PostgresSQL database on Kubernetes with CloudNativePG".
Sign up and explore Distr
Distr is a battle tested software distribution platform that helps you scale from your first self-managed customers to dozens and even thousands.